DetZero: Rethinking Offboard 3D Object Detection with Long-term Sequential Point Clouds
* Corresponding Authors
Existing offboard 3D detectors always follow a modular pipeline design to take advantage of unlimited sequential point clouds. We have found that the full potential of offboard 3D detectors is not explored mainly due to two reasons: (1) the onboard multi-object tracker cannot generate sufficient complete object trajectories, and (2) the motion state of objects poses an inevitable challenge for the object-centric refining stage in leveraging the long-term temporal context representation.
To tackle these problems, we propose a novel paradigm of offboard 3D object detection, named DetZero. Concretely, an offline tracker coupled with a multi-frame detector is proposed to focus on the completeness of generated object tracks. An attention-mechanism refining module is proposed to strengthen contextual information interaction across long-term sequential point clouds for object refining with decomposed regression methods.
Extensive experiments on Waymo Open Dataset show our DetZero outperforms all state-of-the-art onboard and offboard 3D detection methods. Notably, DetZero ranks 1st place on Waymo 3D object detection leaderboard with 85.15 mAPH (L2) detection performance. Further experiments validate the application of taking the place of human labels with such high-quality results. Our empirical study leads to rethinking conventions and interesting findings that can guide future research on offboard 3D object detection.
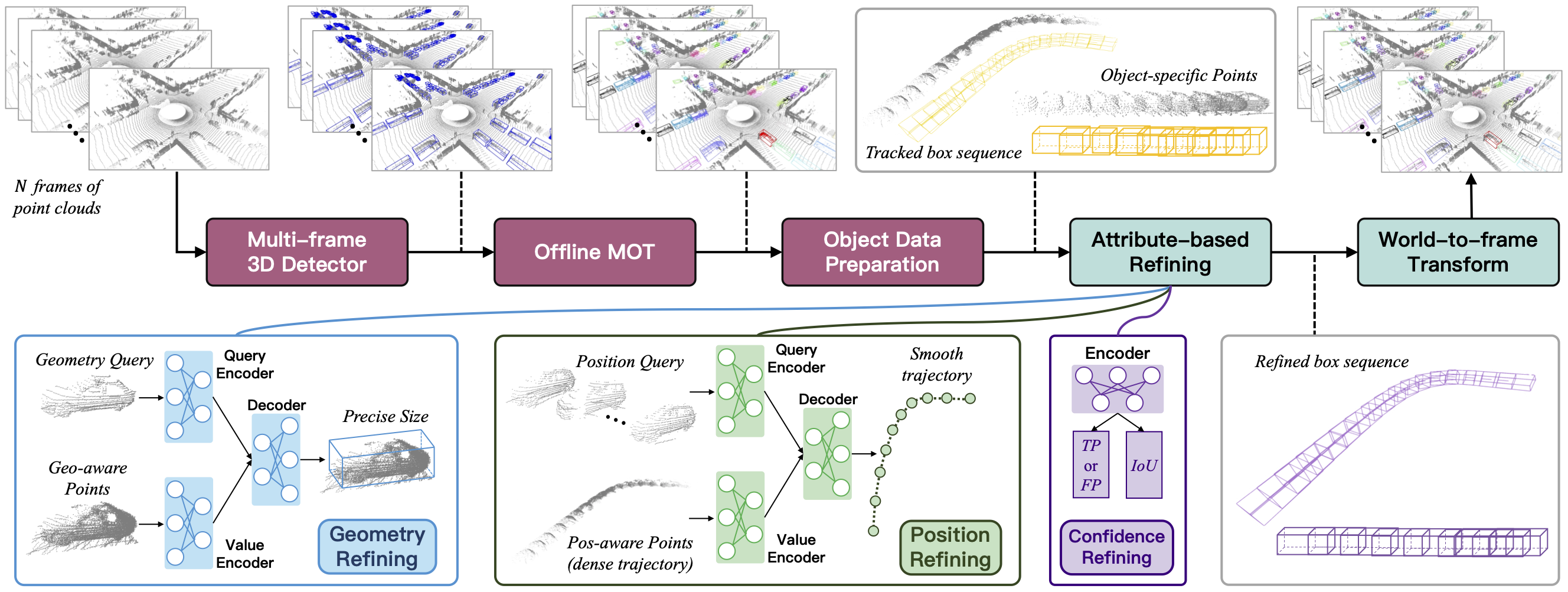
The multi-frame detector takes as input N frames of point clouds, the following offline tracker generates accurate and complete object tracks. For each object track, we prepare its object-specific LiDAR points sequence and tracked box sequence. Consequently, we refine the object tracks through 3 simultaneous steps: refine the geometry size, smooth the motion trajectory and update the confidence score. Afterwards, they are combined together and transformed through world-to-frame poses as the final "auto labels".
@inproceedings{ma2023detzero,
title = {DetZero: Rethinking Offboard 3D Object Detection with Long-term Sequential Point Clouds},
author = {Tao Ma and Xuemeng Yang and Hongbin Zhou and Xin Li and Botian Shi and Junjie Liu and Yuchen Yang and Zhizheng Liu and Liang He and Yu Qiao and Yikang Li and Hongsheng Li},
booktitle = {Proceedings of International Conference on Computer Vision (ICCV)},
year = {2023}
}